爬虫概念:通过编写程序模拟浏览器上网,然后去互联网上抓取数据
通用爬虫:抓取系统的组成部分,抓取一整张页面数据
聚焦爬虫:建立在通用爬虫基础上,抓取页面中特定内容
增量式爬虫:检测网站中数据更新情况,只抓取最新更新的数据
反爬机制/反反爬策略
robots.txt协议:”域名/robots.txt”口头约定是否允许爬取数据
http协议
超文本传输协议
常用请求头信息
1
2
| User-Agent 请求载体的身份标识
Connection 请求完毕后断开或保持连接
|
常用响应头信息
1
| Content-Type 服务器响应客户端数据类型
|
https协议
安全的超文本传输协议(数据加密),采用证书密钥加密
加密方式
对称密钥加密
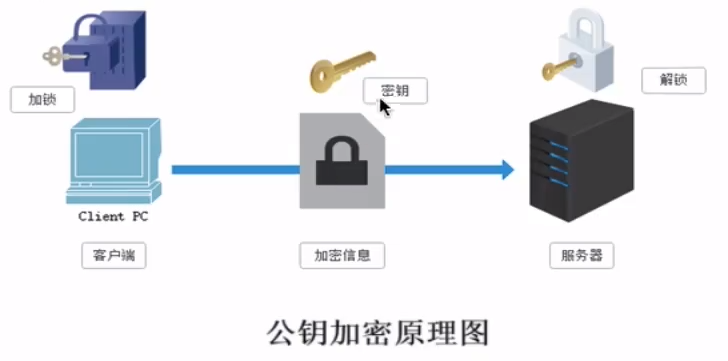
存在安全隐患
非对称密钥加密

效率较低,存在安全隐患
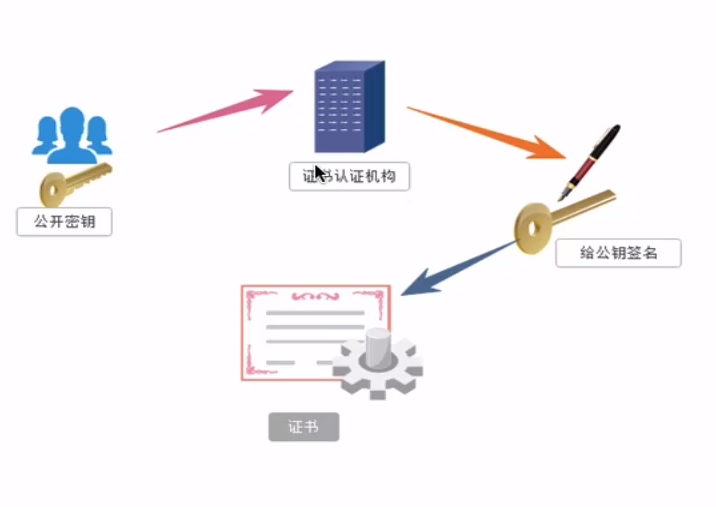
证书密钥加密
requests模块
urllib模块
requests模块
作用:模拟浏览器发请求
1
2
3
| requests.get(url=, params=, headers=) 给params传入字典可以动态拼接成url参数
给headers传入字典可以伪装成某一浏览器
requests.post(url=, params=, headers=) post请求与之类似
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests
if __name__ == '__main__':
url = 'https://www.sogou.com/'
response = requests.get(url=url)
content = response.text
with open('./dataset/sougou.html','w',encoding='utf-8') as fp:
fp.write(content)
|
UA检测:一种反爬机制
门户网站服务器检测请求数据的UA标识,若为爬虫,服务器可能会拒绝该次请求。
UA伪装:对应的反反爬策略
伪装成为某一浏览器
将headers字典传入requests的headers参数中
1
2
3
| headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41'
}
|
实例1:模拟搜索引擎
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import requests
if __name__ == '__main__':
url = 'https://www.sogou.com/web'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41'
}
kw = input('Enter a word:')
param = {
'query': kw
}
response = requests.get(url=url, params=param, headers=headers)
content = response.text
with open('./dataset/'+kw+'.html','w',encoding='utf-8') as fp:
fp.write(content)
|
实例2:爬取豆瓣网电影列表
通过ajax动态请求查看数据请求细节
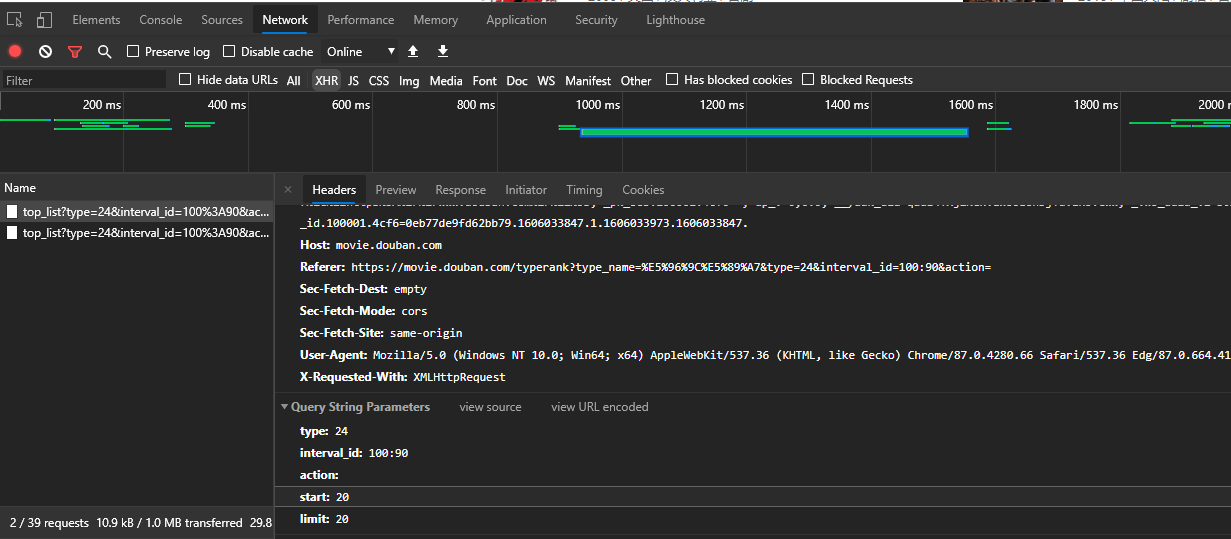
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import requests
import json
if __name__ == '__main__':
url = 'https://movie.douban.com/j/chart/top_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41'
}
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '300'
}
response = requests.get(url=url, params=param, headers=headers)
data = response.json()
with open('./dataset/douban.html', 'w', encoding='utf-8') as fp:
json.dump(data, fp=fp, ensure_ascii=False)
|
数据解析
聚焦爬虫
流程:指定url;发起请求;获取响应数据;数据解析;持久化存储
正则
多语言适用
实例:爬取糗图网图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import requests
import re
import os
if __name__ == '__main__':
if not os.path.exists('../dataset/pics'):
os.mkdir('../dataset/pics')
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41'
}
page_text = requests.get(url=url, headers=headers).text
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(ex, page_text, re.S)
for src in img_src_list:
src = 'https:' + src
img_data = requests.get(url=src, headers=headers).content
img_name = src.split('/')[-1]
img_path = '../dataset/pics'+img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
|
关于re的补充内容

bs4
python独有的方法
需要安装bs4,lxml
实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中
1
2
3
| fp = open('../dataset/test.html', 'r', encoding='utf-8')
BeautifulSoup.(fp, 'lxml')
|
1
2
3
| page_text = response.text
soup = BeautifulSoup(page_text, 'lxml')
|
通过调用BeautifulSoup内置属性或方法进行标签定位和数据提取
1
2
3
4
5
6
7
| soup.标签名 获取第一个该标签的内容
soup.find('标签名') 同上
soup.find('标签名', class_/id/attr='') 指定属性查找
soup.find_all() 符合要求的所有标签
soup.select('') 可以使用某种选择器,返回列表
soup.select('.tang > ul > li >a') 层级选择器 '>'表示一个层级
soup.select('.tang > ul a') 层级选择器 ' '表示多个层级
|
获取标签之间的文本数据/属性值
1
2
3
| sp = soup.select('.tang > ul > li')
sp[0].a.text/string/get_text() 获取a标签文本数据
text/get_text()获取所有文本(可以跨越层级) string仅获取该标签直系文本内容
|
1
| soup.a['href'] 获取a标签中href属性值
|
实例:获取三国演义文本(已失效)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import requests
from bs4 import BeautifulSoup
if _name_"__main__":
headers = {
'User-Agent' : (...)
}
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers)
soup = BeautifulSoup(page_text, 'lxml ')
li_list = soup.select( '.book-mulu > ul > li')
fp = open( './sanguo.txt','w',encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'http://www.shicimingju. com'+li.a[ ' href ']
detail_page_text = requests.get(url=detail_url,headers=headers).text
detail_soup = BeautifulSoup(detail_page_text, 'lxml ')
div_tag = detail_soup.find( 'div', class_='chapter_content')
content = div_tag.text
fp.write(title+':'+content+'\n')print(title '爬取成功!!!')
|
xpath
便捷高效,多语言通用性
只需要安装lxml
实例化一个etree对象,并将页面源码数据加载到该对象中
1
2
| etree.parse(filePath) 本地文件
etree.HTML('page_text') 源码数据
|
通过调用etree对象xpath方法结合xpath表达式进行标签定位和数据提取
1
2
| tree = etree.parse(filePath)
tree.xpath('/html/head/title') 从外向内定位,返回element对象的列表
|
xpath表达式详解
下列表达式返回值都为列表
1
2
3
4
5
6
7
| /html/div/li/a '/':一个层级
/html//a 或 //a '//':多个层级
//div[@class="song"] 属性定位
//div[@class="song"]/p[3] 对p标签进行索引(索引从1开始)
//div/text() 获取文本内容(只能获取本层子内容)
//div//text() 获取文本内容(全部内容,可传递)
//div[@class="song"]/img/@attr 获取attr属性的内容
|
实例:获取58同城房产信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import requests
from lxml import etree
if __name__ == '__main__':
url = 'https://bj.58.com/ershoufang/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41'
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
fp = open('../dataset/58.txt', 'w', encoding='utf-8')
for li in li_list:
title = li.xpath('./div[2]/h2/a/text()')[0]
print(title)
fp.write(title+'\n')
|
反爬机制
验证码
第三方自动识别