JVM相关问题

JVM位置
JVM处于Java程序之下,os操作系统之上
java程序执行过程
注:jdk1.8后,方法区在堆中的元空间中,这里为了直观表现将其单独划分出来
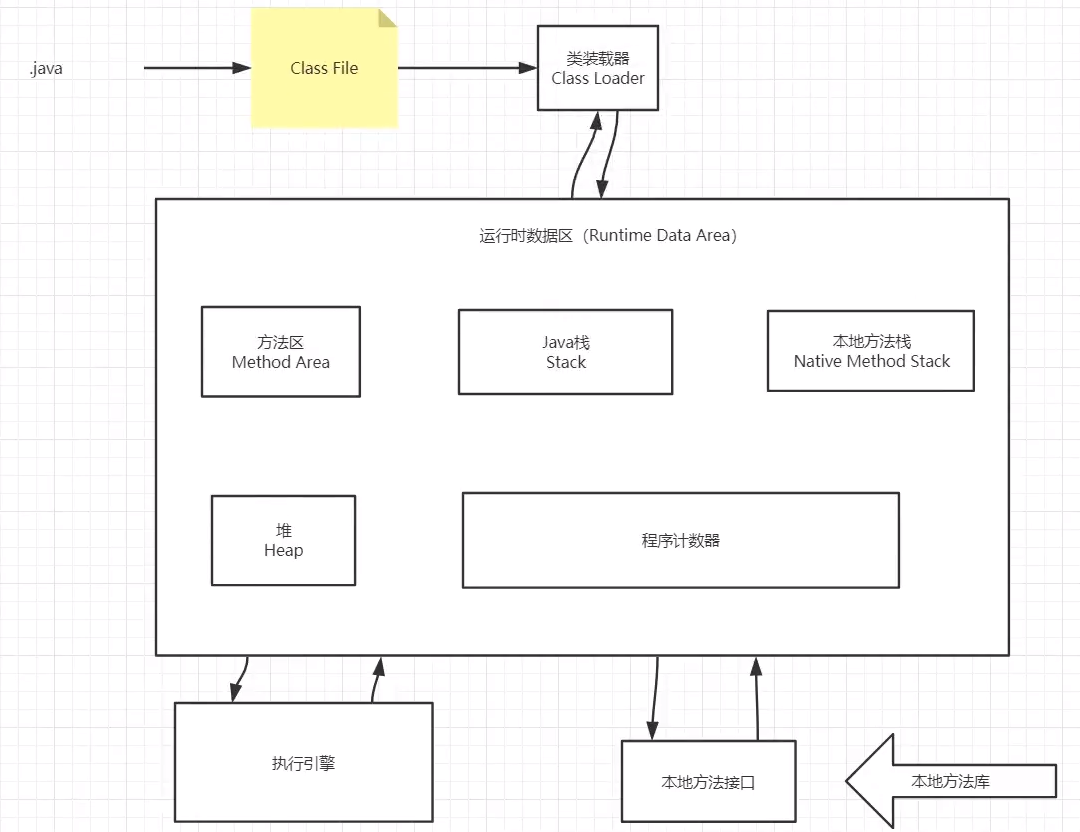
栈和程序计数器中不会有垃圾,JVM调优一般指对堆进行调优
类加载器
作用:加载Class文件
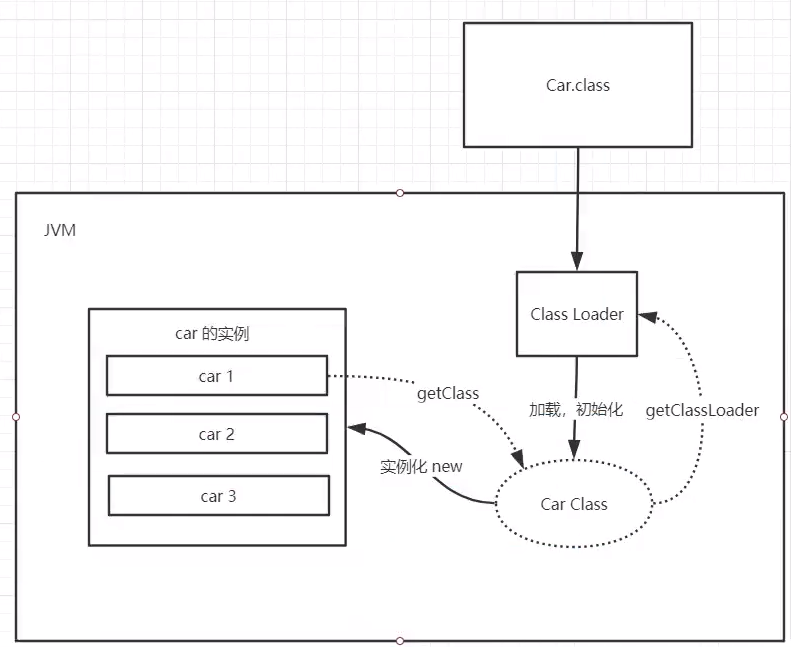
虚拟机自带加载器
- 启动类(根)加载器
- 扩展类加载器B
- 应用程序加载器
双亲委派机制(安全):APP->EXC->BOOT(最终执行)
- 类加载器收到类加载的请求
- 将请求向上委托给父类加载器去完成,一直向上委托,直到启动类加载器
- 启动加载器检查是否能加载当前类,能加载就结束,使用当前加载器,否则抛出异常,通知子加载器进行加载
- 重复步骤3,如果最终APP加载器也未找到,则class not found
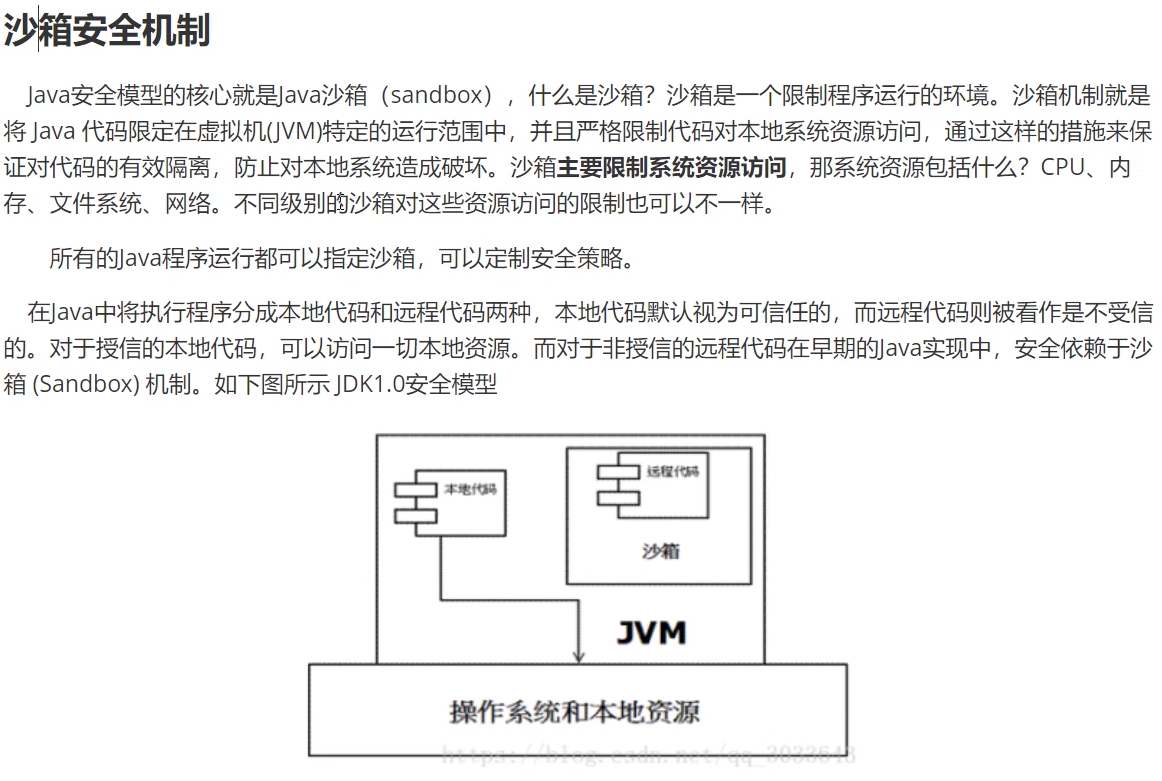
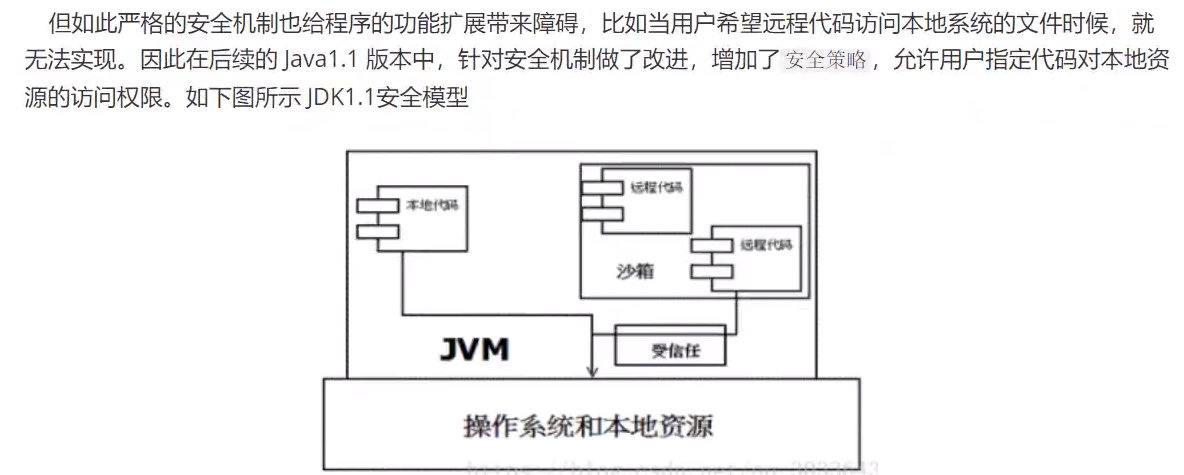
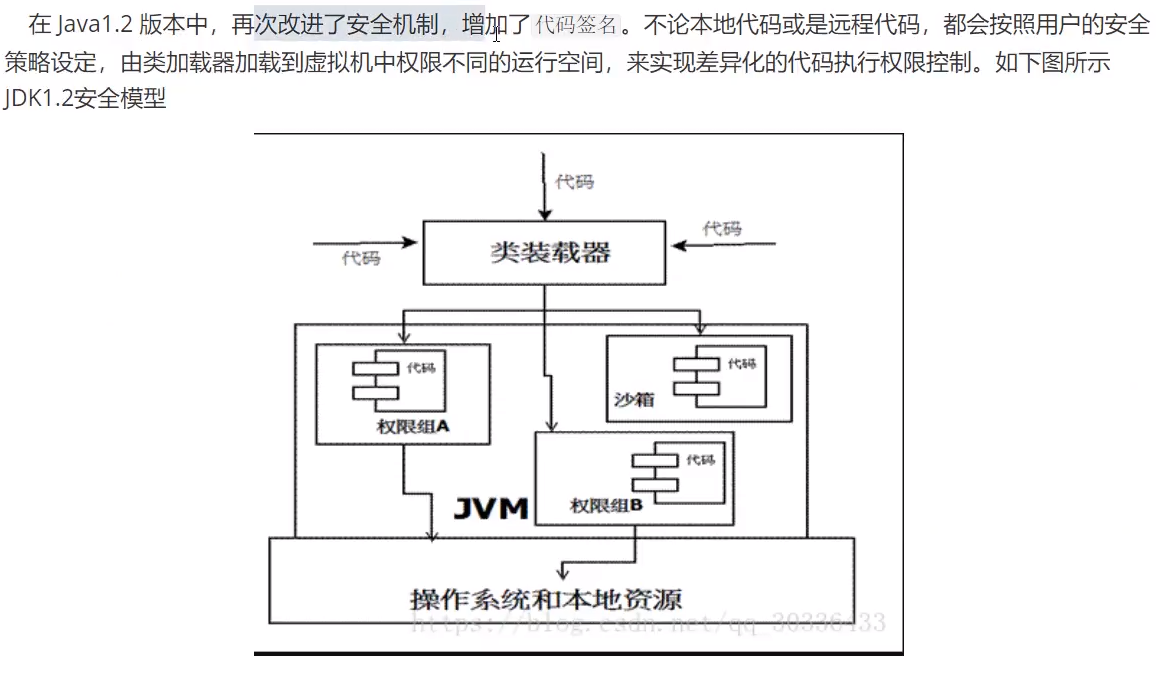
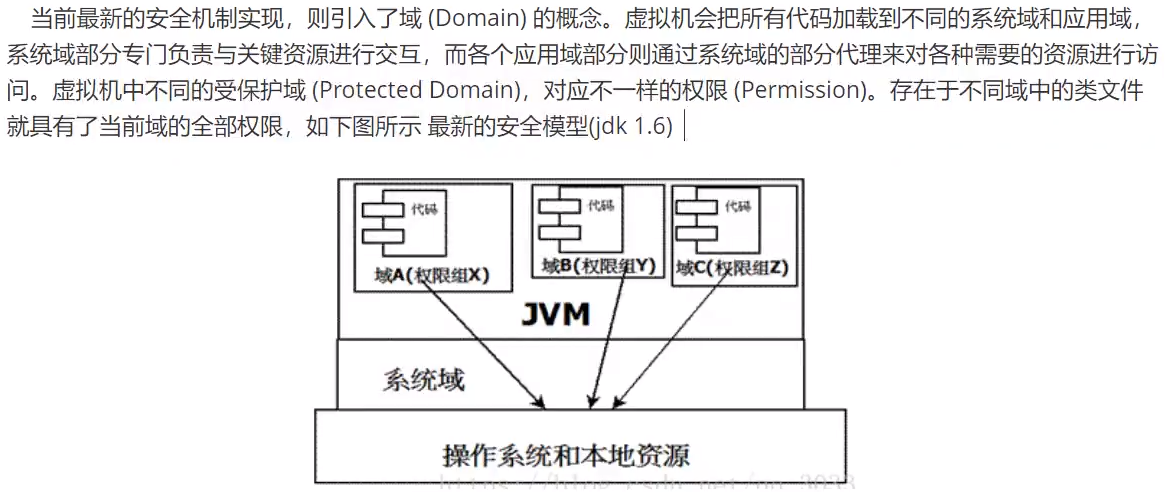
沙箱安全机制(了解)
对于远程代码所添加安全性评估


Native关键字

带native关键字的说明java的作用范围无法达到,调用了底层C语言库,进入本地方法栈,调用本地方法本地接口JNI(Java Native Interface)
JNI作用:扩展Java使用,融合不同的编程语言为Java所用,最初有C和C++;他在内存中专门开辟一块标记区域:Native Method Stack,等级native方法;最终执行时,加载本地方法库中的方法通过JNI
用于驱动打印机,管理系统等
PC:程序计数器
每个线程私有的一个指针,指向方法区中的方法字节码,在执行引擎读取下一条指令,内存空间很小
方法区
静态变量(static)、常量(final)、类信息(Class),运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关
java栈
先进先后,后进先出(main()方法最先执行,最后结束)
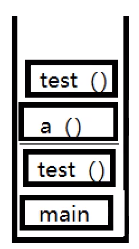
存储内容:8大基本类型,对象引用,实例方法
运行原理:栈帧

栈满后抛出错误:StackOverflowError
Java种类
- Sun公司Hotspot(主修)
- BEA JRsocket
- IBM J9 VM
堆
一个JVM只有一个堆内存,堆内存的大小是可以调节的
类加载器读取了类文件后,一般把
类、方法、常量、变量,保存我们所有引用类型的真实对象堆内存
新生区(伊甸园区)
类诞生和成长的低方,所有对象都是在伊甸园区new出来的
伊甸园区
幸存区0区(from区)
幸存区1区(to区)
from区和to区会轮流交换,而to区一般为空:为了平衡空间,内存占用多的区会将对象移向内存较小的区,即from被占用内存多to空区
养老区(老年区)
永久区
(jdk8以后,永久区更名为元空间)
- jdk1.6前:永久代,常量在方法区
- jdk1.7:永久代,慢慢退化(区有就代),常量在堆中
- jdk1.8之后:无永久代,常量池在元空间
方法区(非堆)也在元空间中,而常量池在方法区中
常驻内存,用来存放jdk自身携带的Class对象,Interface元数据,存储的是Java运行时的一些环境或类信息,该区域不存在垃圾回收,关闭VM虚拟机会释放这个区域的内存
警告:启动类加载了大量的第三方jar包,Tomcat部署了太多应用或大量动态生成的反射类,不断被加载直到内存满,也会出现OOM
垃圾回收
GC垃圾回收主要是在伊甸园区和养老区,假设内存都满了,堆内存不够,抛出错误:OutOfMemoryError
- 轻GC
- 重GC(Full GC)
新生区的子区伊甸园区满后触发一次轻GC,过滤后的对象进入幸存区0区,新生区的三个子区都满后触发一次重GC,过滤后的对象进入养老区
经研究,99%的对象都是临时对象
在计算内存时元空间逻辑上存在,物理上不存在
通过添加VM option
-Xms1024m -Xmx1024m -XX:+PrintGCDetails来自定义虚拟机参数r1
2
3
4-Xms 设置初始化内存分配大小,默认1/64
-Xmx 设置最大分配内存,默认1/4
-XX:+PrintPrintGCDetails 打印GC垃圾回收信息
-XX:+HeapDumpOnOutOfMemoryError 当发生OutOfMemoryError时dump出内存文件,可被jprofiler等调优软件读取
经计算新生区和养老区大小之和为实际堆占用大小,即堆内存未计算元空间大小
MAT,Jprofiler等调优器作用
- 分析Dump内存文件,快速定位内存泄漏
- 获得堆中数据
- 获得大对象等
GC:垃圾回收机制
两种类型:轻GC/重GC
GC常用算法:
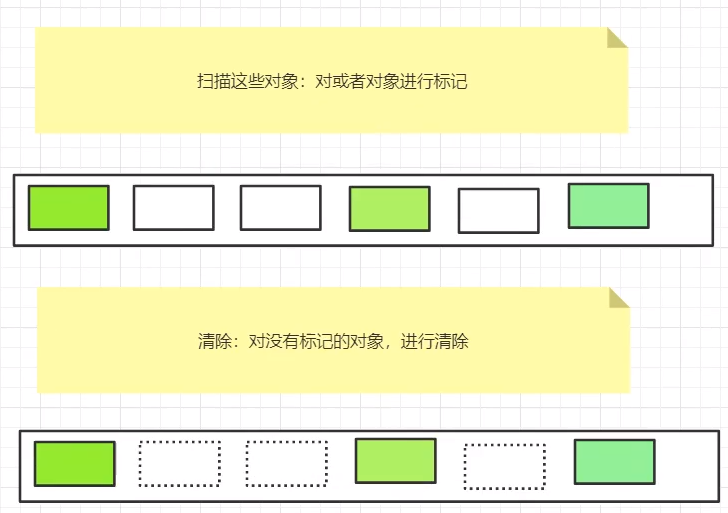
标记清除法
第一阶段:标记。从根结点出发遍历对象,对访问过的对象打上标记,表示该对象可达。
第二阶段:清除。对那些没有标记的对象进行回收,这样使得不能利用的空间能够重新被利用。
优点:不需要额外空间
缺点:两次扫描严重浪费时间,会产生内存碎片
标记压缩(标记整理)
对标记清除法的优化
可以先标记清除多次再进行标记压缩(标记清除压缩)
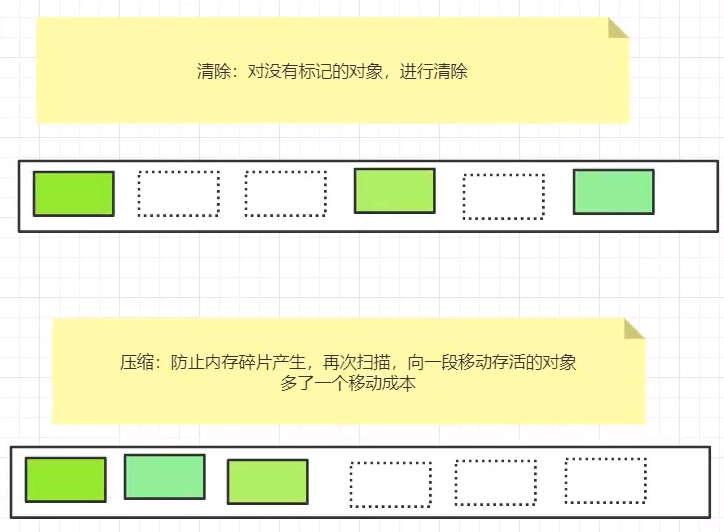
优点:防止内存碎片产生
缺点:又增加了一次扫描时间和移动成本
复制算法
每次GC都会将Eden区的对象移至幸存区,而Eden区被GC后就会变空,两个幸存区中,谁空谁是to区
一个对象经历了15次GC(默认)都没有死时会进入养老区
用
-XX:MaxTenuringThreshold=9设置参数可以设定进入养老区所需GC次数为9复制算法一般用于年轻代GC,如图所示
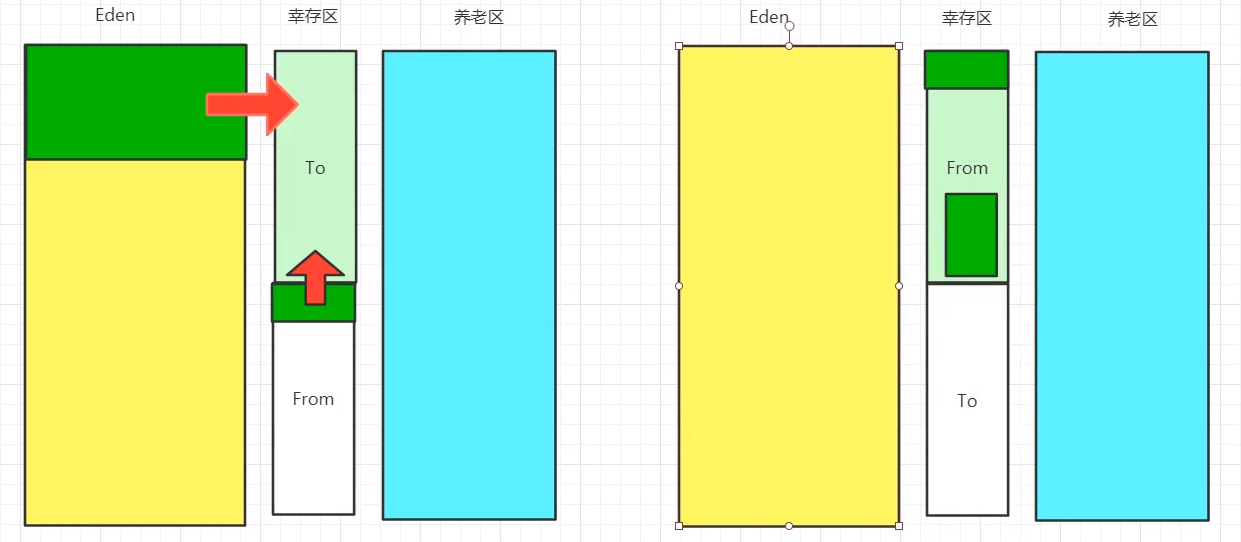
优点:没有内存碎片,对象存活度较低时使用效果好
缺点:浪费一半的幸存空间
引用计数器
给每个计数器创造专属计数器并赋值为0,每当一个对象被引用便给它的计数器+1,触发GC时淘汰计数器数值小的数个对象
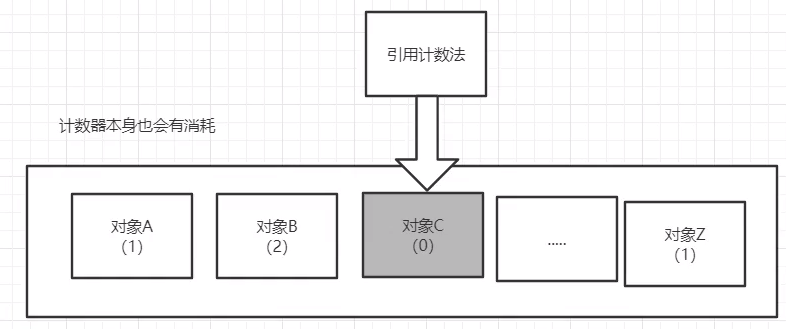
缺点是计数器本身也要占用内存,因此在JVM中不应用此方法
GC总结
- 内存效率:复制效率>标记清除算法>标记压缩算法(时间复杂度)
- 内内存整齐度:复制算法=标记压缩算法>标记清除算法
- 内存利用率:标记压缩算法=标记清除算法>复制算法
没有最好的算法,只有最合适的算法
GC:分代收集算法
- 年轻代:存活率低:复制算法
- 老年代:区域大,存活率高:标记清除+标记压缩混合实现
JMM(Java Memory Model)
作用:缓存一致性协议,用于定义数据读取的规则;定义了线程工作内存和主内存之间的抽象关系:线程之间的共享变量储存在主内存中,每个线程都有一个私有的本地内存
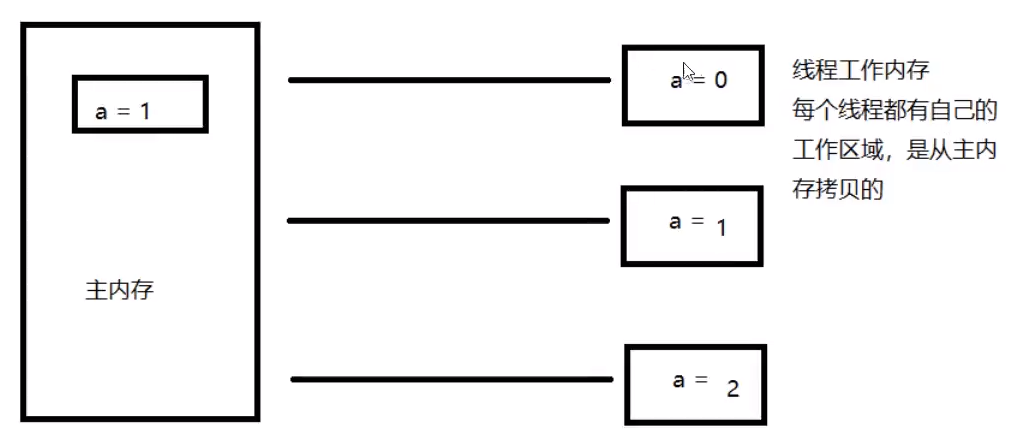
解决共享对象可见性问题:volilate关键字
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
JMM对这八种操作规则和对volatile的一些特殊规则就能确定哪里操作是线程安全,哪些操作是线程不安全的了。但是这些规则实在复杂,很难在实践中直接分析。所以一般我们也不会通过上述规则进行分析。更多的时候,使用java的happen-before规则来进行分析。