基础知识
中间件技术
一些常用的中间件技术
- 分布式消息中间件
- ActiveMQ
- RabbitMQ
- Kafka
- RocketMQ
- 负载均衡中间件
- Nginx
- LVS负载均衡
- KeepAlive
- CDN
- 缓存中间件
- MemCache
- Redis
- 数据库中间件
- Mycat
- ShardingJdbc
MQ解决的问题
- 流量消峰
- 应用解耦
- 异步处理
MQ协议
AMQP协议
特性:
- 分布式事务
- 消息持久化
- 高性能和高可靠的消息处理
支持RabbitMQ,ActiveMQ
MQTT协议
特性:
轻量级
结构简单
传输快
不支持持久化
支持RabbitMQ,ActiveMQ
OpenMessage协议
特性:
- 结构简单
- 解析速度快
- 支持事务和持久化
支持RocketMQ
Kafka协议
特性:
- 结构简单
- 解析速度快
- 不支持事务
- 可以持久化
支持Kafka
MQ相关概念
MQ中的角色
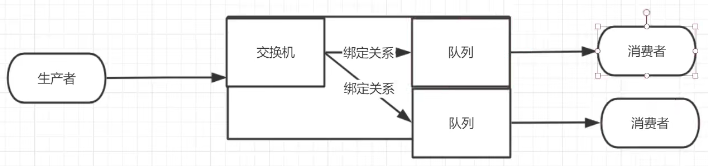
生产者、交换机、队列、消费者
RabbitMQ工作原理
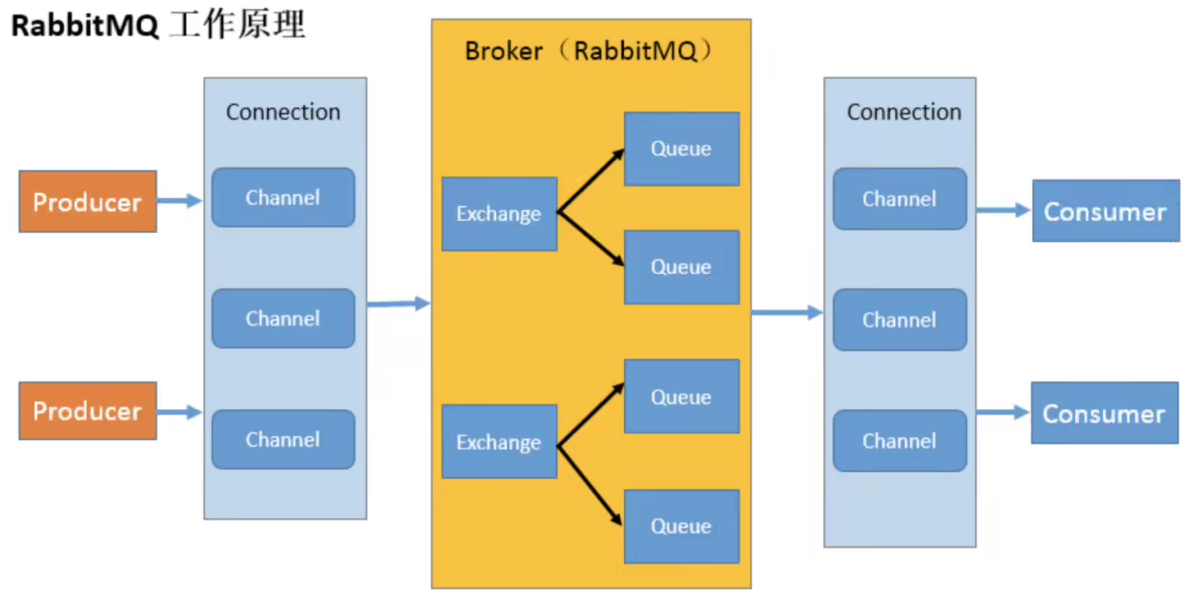
开始RabbitMQ
安装和配置
安装
官方下载文档Downloading and Installing RabbitMQ — RabbitMQ
手动安装还需要Erlang语言环境的支持,安装较为繁琐,因此这里使用docker安装
1 | # for RabbitMQ 3.8, |
我们安装的RabbitMQ是带有RabbitManagement的,不需要额外开启功能,如果是手动安装的RabbitMQ需要先停止server再开启服务:
1 | rabbitmq-plugins enable rabbitmq_management |
进入15672端口,如果没有配置过,则默认用户名和密码都是guest
RabbitMQ用户管理
1 | rabbitmqctl list_users #查看所有用户 |
一些常用命令

HelloRabbitMQ
注意提前开放5672端口
配置依赖
1 | <!--RabbitMQ客户端--> |
生产者
1 | public class Producer { |
消费者
1 | public class Consumer { |
实际上消费者的两个失败的回调函数在正常执行过程中并不会触发,而是在不断监听,一旦有新的消息来到就会立即接收
工作模式
简单模式
我们上面做的例子就是简单模式的一个实现,并且是RabbitMQ的默认工作模式
提取工具类RabbitMqUtil.java
1 | public class RabbitMqUtil { |
交换机的类型
- Fanout:广播
- Direct:定向
- Topics:通配符
WokerQueues
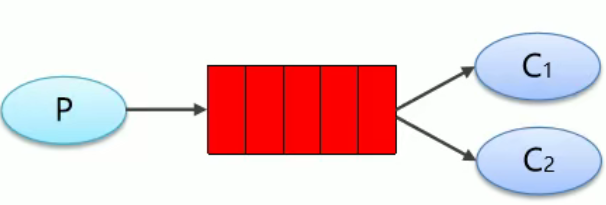
工作队列模式:采用轮训的方式,只有一个消费者能够取得队列中的消息,消费者轮流取得消息信道中的信息
Pub/Sub
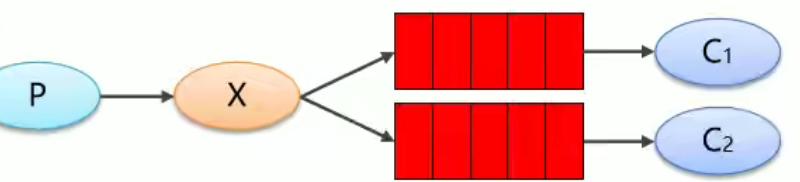
订阅模式:
X:交换机
生产者
1 | public void exchange() throws IOException { |
消费者代码与之前类似
Routing
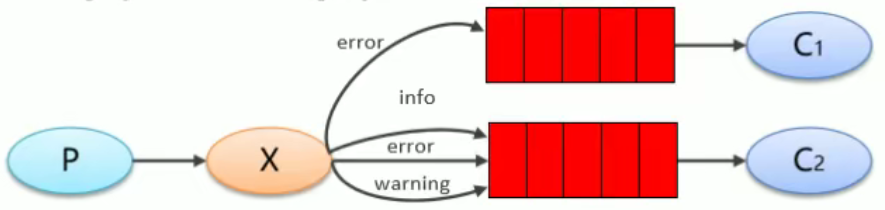
路由模式:生产者携带的RountingKey与指定类型匹配时才会发送到相应信道
这里仅给出特有的代码实现
1 | //创建交换机更改枚举类型 |
1 | //绑定队列1与key:error |
1 | //发布消息指定routingKey,这里是error,两个信道都能收到消息 |
Topics
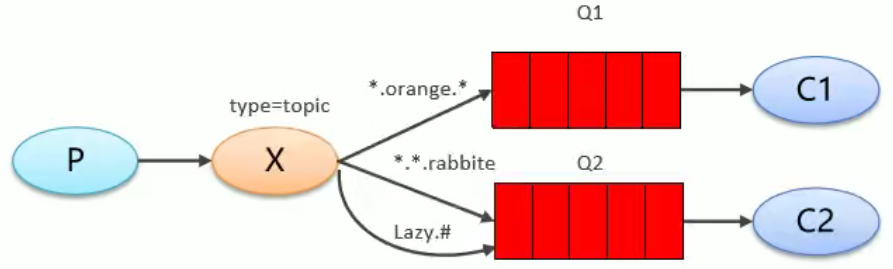
通配符模式:将routingkey指定为通配符,不需要完全匹配
这里仅给出特有的代码实现
1 | //创建交换机更改枚举类型 |
- 路由键和绑定键的字符串会切分成单侧,单词之间用
.分开 #表示匹配0个或多个单词*表示匹配一个单词
1 | //绑定队列1与key:'*.error' |
1 | //发布消息指定routingKey,这里是'user.error',两个信道都能收到消息 |
整合SpringBoot
配置环境
包依赖
1 | <!--引入amqp协议,即RabbitMQ的依赖--> |
配置文件
1 | spring: |
RabbitTemplate
使用RabbitTemplate发送和接收消息
1 |
|
由于默认使用的是jdk序列化,如果我们需要可以注入我们自己的MessageConverter,使其转换为json序列化
1 |
|
注意:在使用Json序列化之后我们如果需要手动在网页端发送消息也需要使用Json的序列化格式发送
注解开发RabbitMQ
主类上添加@EnableRabbit以开启注解功能
使用注解监听队列
RabbitListener
方法上使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class RabbitService {
//转换器会将消息内容自动转换为实体类
public void listenQue1(User user){
System.out.println(user.getClass());
System.out.println(user.toString());
}
//使用Message接收消息能够拿到消息的完整信息
public void listenQue2(Message message){
System.out.println(message.getClass());
System.out.println(message.toString());
}
}
类上使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
* 通过queuesToDeclare来声明队列
* ,@Queue注解创建临时队列
* 还可以进行一些que的详细配置
*/
public class customer {
//标注这个方法是收到消息后的回调方法
public void receive(String message){
System.out.println(message);
}
}
AmqpAdmin
通过AmqpAdmin就可以进行消息队列的一系列操作
1 |
|
使用临时队列
下面两段代码并没有直接关联,只是展示了生产者和消费者不同的实现方式
生产者实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/**
* 向容器中注入交换机、队列、Binding组件就会自动临时创建
*/
public class priQueue {
private static final String EXCHANGE = "springboot.mq";
public static final String QUEUE = "que1";
private static final String ROUTING_KEY = "user.info";
//注入交换机
DirectExchange exchange1(){
return new DirectExchange(EXCHANGE);
}
//注入队列
Queue queue1(){
Map<String,Object>map = new HashMap<>();
map.put("x-max-priority",10);//设置最大的优先级数量
return new Queue(QUEUE,true,false,false,map);
}
//注入Binding
public Binding binding1(){
return BindingBuilder.bind(queue1()).to(exchange1()).with(ROUTING_KEY);
}
}消费者实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 通过queuesToDeclare来声明队列
* ,@Queue注解中还可以进行一些详细配置
*/
public class customer {
//标注这个方法是收到消息后的回调方法
public void receive(String message) {
System.out.println(message);
}
}
高级特性
以下的代码都基于SpringBoot实现
消息可靠投递
- confirm确认模式
- return退回模式

confirm模式
修改配置文件
1 | : correlated |
测试代码
1 |
|
return模式
如果消息没有路由到Queue的处理方式:
- 丢弃消息(默认)
- 返回给发送方ReturnCallBack
修改配置文件
1 | : true |
1 |
|
Consumer Ack
消费端收到消息之后的确认方式
三种确认方式:
- 自动确认:acknowledge=”none”
- 手动确认:acknowledge=”manual”
- 根据异常类型确认:acknowledge=”auto”
注意只有simple和direct模式可以设置手动确认,需要指定相应的交换器为simple或direct类型
修改配置文件
1 | spring: |
向容器中注入ChannelAwareMessageListener
1 |
|
消费端限流
1 | spring: |
TTL
存活时间:指定时间后未被消费的消息会被自动清除
可以对单个消息进行设置,也可以对整个队列进行设置
队列设置
创建队列时添加参数,时间单位为毫秒
网页实现
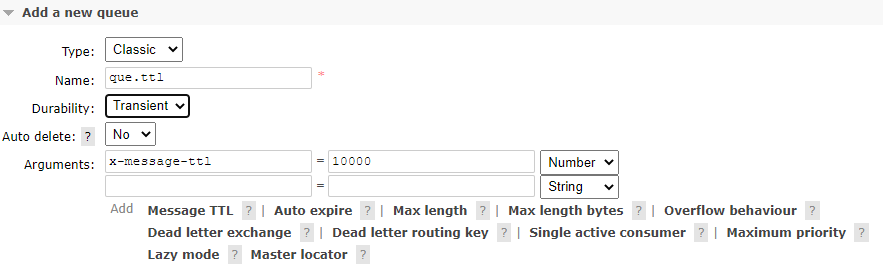
代码实现
自定义Que
1
2
3
4HashMap<String, Object> map = new HashMap<>();
//通过map设置参数,参数名必须为指定的参数名,可以在网页端查看
map.put("x-message-ttl",10000);
amqpAdmin.declareQueue(new Queue("custom.que",true,false, false, map));使用QueBuilder
1
2Queue queue = QueueBuilder.nonDurable("my.que").ttl(10000).build();
amqpAdmin.declareQueue(queue);
单消息设置
1
2
3
4
5rabbitTemplate.convertAndSend("springboot.mq", "user.info", "test message", message -> {
//设置TTL
message.getMessageProperties().setExpiration("10000");
return message;
});
如果设置了队列过期时间的同时设置了单个消息的过期时间
- 队列过期时,会将队列所有消息全部移除
- 消息一入队列就会判断这个消息的过期条件,但只有当这个消息在消息队列的顶部时才会决定是否移除
死信队列DLX
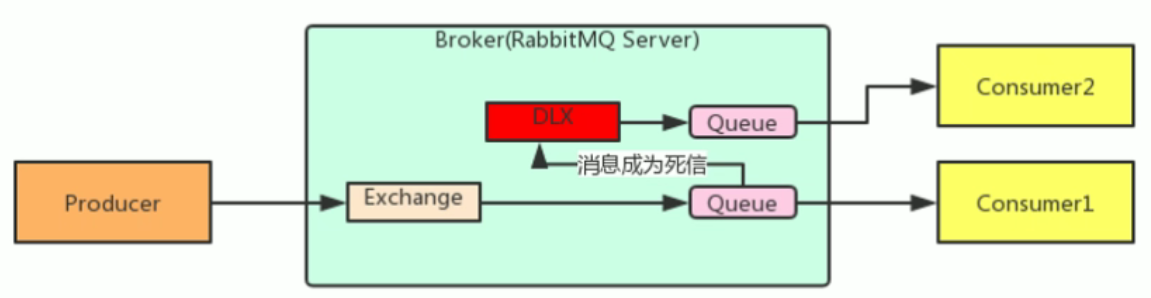
Dead Letter Exchange:当消息成为Dead message之后,可以被重新发送到另一个交换机,这个交换机就是DLX
DLX实际上与一般的交换机没有什么区别,只是因为我们使用的功能不同,将其划分为DLX
消息成为死信的三种情况:
- 队列消息长度达到上限
- 消费者拒接消费消息:basicNack/basicReject,并且不把消息重新放回原消息队列:requeue=false
- 原消息队列存在消过期设置,消息超时未被消费
具体实现
normal.exchange绑定normal.que
normal.que需要配置四个参数:
x-message-ttl, x-max-length, x-dead-letter-exchange, x-dead-letter-routing-key对应最大ttl,队列最大长度,DLX交换机,DLX交换key
dead.exchange绑定dead.que
备份交换机
原理与死信队列类似,目的是防止主交换机在使用过程中宕机
使用方法,创建交换机时添加参数alternate-exchange
延迟队列
消息进入队列后不会立即被消费,而是到达指定时间后才会被消费
RabbitMQ并没有提供延迟队列的功能,不过我们可以使用TTL+DLX的组合实现延迟队列我的效果,如下图为检查用户是否支付的流程图
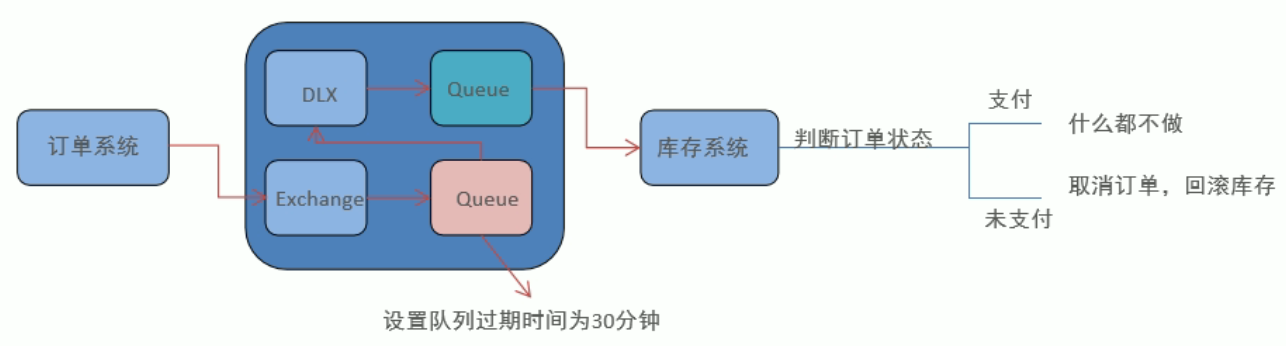
这里就因为与上面死信队列的例子类似,具体实现省略
幂等性问题
如果用户在支付业务中由于网络延迟在同一业务中发送了多条支付信息,如何保证最终仅执行一次业务?
一般使用全局ID,每次消费消息时判断是否已经消费过
唯一ID+指纹码
利用一些手段生成唯一信息码,判断id是否存在数据库中,但在高并发场景可能会有性能问题
Redis原子性(推荐)
利用Redis执行setnx操作,天然具有幂等性,实现不重复消费
优先级队列
优先级队列0~255,优先级越大越优先执行
添加/声明队列时添加参数
x-max-priority:表示允许设置的最大优先级发送方式
1
2
3
4
5rabbitTemplate.convertAndSend("springboot.mq", "user.info", "test message", message -> {
//设置优先级
message.getMessageProperties().setPriority(5);
return message;
});
惰性队列
消息保存在内存中还是磁盘中?
惰性队列的消息是保存在磁盘中的
使用场景:消费者下线,宕机等原因长时间不能消费造成堆积时
在发送100W消息,每条消息大概占1KB时,不同队列占用内存1.2GB,惰性队列仅占用内存够1.5MB,性能提升很高
- 正常情况:消息保存在内存中
- 惰性队列:消息保存在外存中
创建队列时携带参数x-queue-mode = lazy即可开启
系统操作
日志与监控
日志
默认存放位置/var/log/rabbitmq/rabbit@主机名.log
使用docker在容器内路径/var/log/rabbitmq/log
消息追踪
消息追踪会降低性能,一般只在生产和测试环境开启
打开trace相关配置
1 | rabbitmqctl trace_on |
这时在网页控制台的Admin界面的右侧出现新的选项:Tracing
在这里我们可以添加自己的消息追踪文件
需要注意的是,只有用户名和密码都为guest用户才能添加trace,否则会报错,具体原因未知
内存管理
rabbitmq默认内存为总内存的40%
修改可用内存大小
当发现内存爆满,连接全部挂起的情景时,选择其中一种方式即可
1 | rabbitmqctl set_vm_memory_high_watermark 百分比 #设置百分比,一般取值为0.4~0.7 |
修改预警外存大小
当可用的外存大小小于指定值时开始预警
集群搭建
集群模式
主备模式
正常情况下备用节点不提供服务
也就是一个主/备方案,主节点提供读写,备用节点不提供读写。如果主节点挂了,就切换到备用节点,原来的备用节点升级为主节点提供读写服务,当原来的主节点恢复运行后,原来的主节点就变成备用节点,和 activeMQ 利用 zookeeper 做主/备一样,也可以一主多备。
远程模式
早期模式,目前使用较少
主机作负载均衡,超过阈值的数据交由副机处理
镜像模式
节点之间的数据可以进行同步
多活模式
多个负载均衡的数据节点集群

搭建集群
注意点(无论是不是使用docker):
- 主机名的设置
- 使用相同的Cookie文件
创建三个RabbitMq容器
官方推荐使用--erlang-cookie来代替RABBITMQ_ERLANG_COOKIE
1 | docker run -d --hostname rabbitmq --name rabbitmq -p 15672:15672 -p 5672:5672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.8-management |
配置三个容器
rabbitmq
1
2
3
4
5docker exec -it rabbitmq bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exitrabbitmq-s1
–ram表示设置为内存节点
1
2
3
4
5
6docker exec -it rabbitmq-s1 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq
rabbitmqctl start_app
exitrabbitmq-s2
1
2
3
4
5
6docker exec -it rabbitmq-s2 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq
rabbitmqctl start_app
exit
如果内存不足可以使用命令来设置最大内存
1 | rabbitmqctl set_vm_memory_high_watermark absolute 400MB |
效果

解除集群的命令
1 | docker exec -it rabbitmq-s1 bash |
配置镜像集群
现在我们搭建的集群是主备模式,不具备同步队列的功能的,如果主节点宕机,其中的消息会全部丢失
开启方法:
在网页管理面板点击上方Admin,再选择右边Polices,添加策略,这里给出一个示例
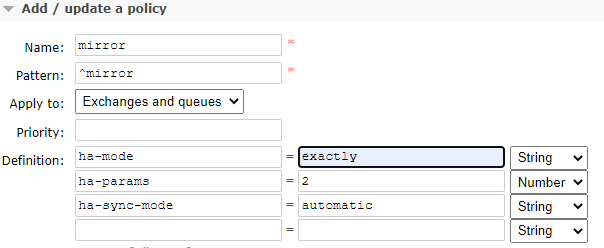
这些配置表示:匹配前缀为mirror的所有交换机和队列,将他们备份2份(主机+从机一共2份),使用自动选择模式,即系统为我们选择在哪一台从机上备份
查看效果:
手动创建一个新的队列,已经备份成功的队列会有显示

联邦模式
联邦交换机
两个不同地区的服务器A,B:A地的用户想要查看B服务器中的数据,B地的用户想要查看A服务器中的数据
开启方式:在每台机器上进行配置
1 | rabbitmq-plugins enable rabbitmq_federation |
数据由上游同步给下游,联邦交换机时交换机之间的通讯
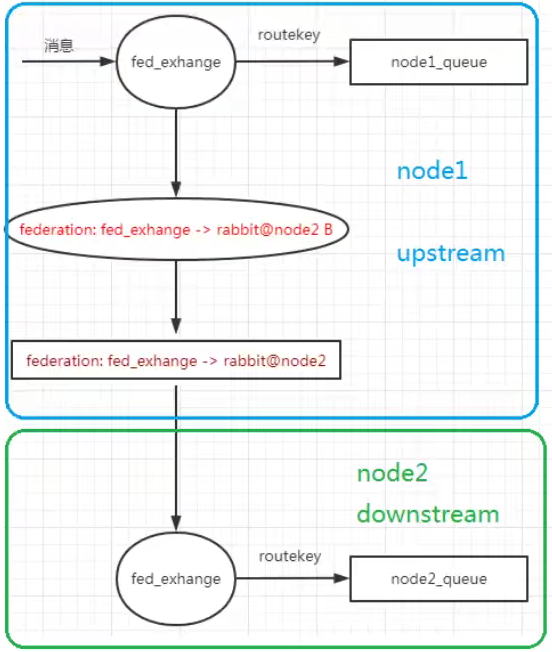
先创建上游交换机:上游
up.exchange打开右侧的Federation Upstreams,配置上游的节点信息
url格式:
amqp://用户名:密码@上游节点名
打开右侧的Polices,为下游交换机配置上游节点
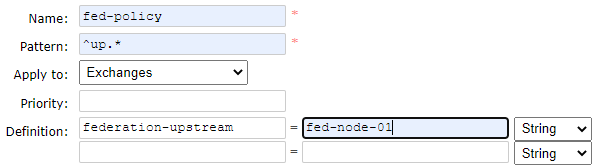
配置成功之后可以在右侧Federation Status查看到联邦运行信息

联邦队列
创建步骤与联邦交换机类似:
创建上游队列
up.que配置上游节点信息(如果已经配置则跳过)
添加Polices(把Apply to改为Queues)
查看节点信息

Shovel
也是一种同步数据的实现方式
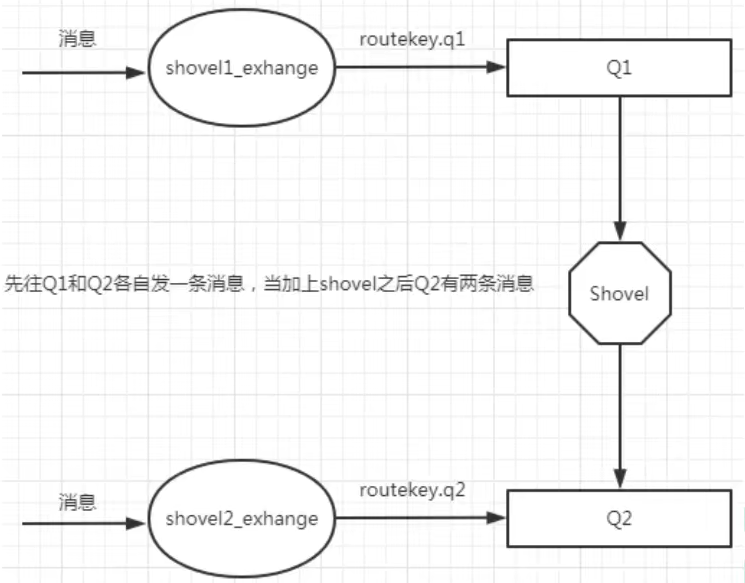
开启方式:在每台机器上进行配置
1 | rabbitmq-plugins enable rabbitmq_shovel |
Source端创建队列Q1,Destination端创建队列Q2,配置shovel:
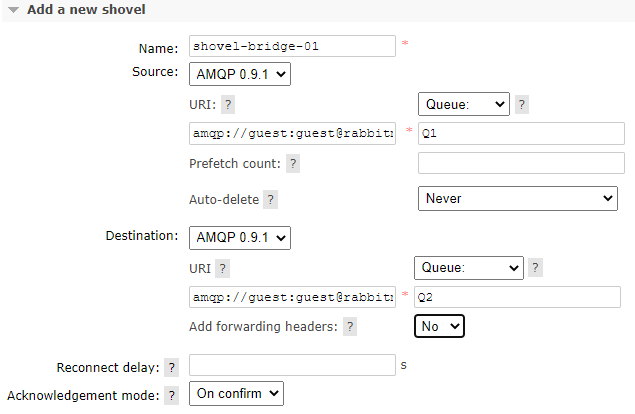
查看状态信息
