Redis特点
NoSQL特点
- 大数据高性能(Redis一秒写8w次,读11w次,细粒度的关村,性能较高)
- 数据类型多样性,不需要实现设计数据库,随取随用,键值对存储,列存储,文档存储,图形数据库
- 方便扩展(数据之间没有关系,容易扩展)
- 没有固定查询语言
- 最终一致性
- CAP定理和BASE (异地多活)
大数据特点
- 3V:描述问题
- 海量Volume
- 多样Variety
- 实时Veiocity
- 3高:对程序的要求
- 高并发
- 高可用(随时水平拆分)
- 高性能(保证用户使用)
NoSQL分类
KV键值对:Redis
文档型数据库:
- MongoDB:分布式文件存储的数据库,c++变编写,一个介于关系型和非关系型之间的产品
- CouchDB
列存储数据库:HBase
图关系数据库:Neo4j,InfoGrid
用来存储对象之间的关系网图,如社交关系网
Redis:Remote DIctionary Server
特点
- 内存存储,持久化(rdb,aof)
- 效率高,用于高速存储
- 发布订阅信息
- 地图信息分析
- 计时器、计数器(浏览量等)
- Redis的常见用途:数据库、缓存、消息中间件MQ
为什么Redis是单线程的?
Redis给予内存操作,Redis的性能瓶颈不是CPU,而是机器的内存和网络带宽,既然可以使用单线程来实现,就没必要用多线程
- 避免线程上下文切换开销
- 避免线程同步机制的开销
- 如果是多线程模型就需要设计底层线程安全的数据结构,这会让redis更加复杂
Redis是多线程吗?
- Redis4.0(引入多线程处理异步任务)
- Redis6.0(在网络模型中实现多线程IO)
一般讨论的单线程Redis一般指Redis6.0之前的单线程多路复用网络模型
但Redis6.0执行实际任务仍然是单线程,除非是非阻塞命令,如:UNLINK, FLUSHALL ASYNC, FLUSHDB ASYNC
Redis配置
安装和运行
Redis官方推荐在linux上进行redis的部署,github的windows版本已经停更许久
redis默认端口号6379
操作流程:
直接解压
redis-6.2.5.tar.gz安装依赖
yum install gcc-c++gcc -v检查版本redis目录中运行
makeredis默认不是后台启动的,需要修改配置文件,我们可以将make文件同级目录的
redis.conf文件拷贝一份到我们指定的目录,以防止错误配置报错,同时对其进行修改,开启守护进程模式
redis默认指令在make目录下的src目录,进入后输入指令,指定配置文件并运行redis服务器
1
./redis-server ../redis.conf #后面的参数使我们自己的配置文件路径
启动客户端
1
./redis-cli [-h 主机ip] -p 6379 #默认主机ip为本机,可以不写
客户端测试连接
ping,如果出现PONG的返回提示即运行成功查看进程
ps -ef|grep redis
客户端关闭服务
shutdown
测试性能
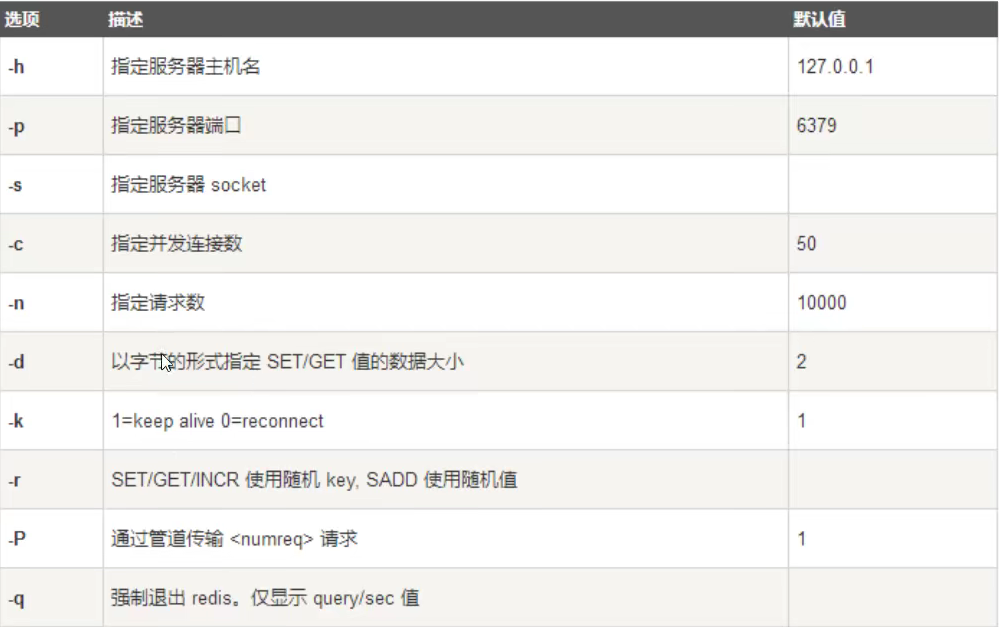
redis-benchmark:压力测试工具
指令示例
1 | #100个并发客户端 100000条请求 |
RedisKey基础操作
redis默认有16个数据库,默认使用第’0’个
可以使用
select 编号来切换数据库查看db大小
dbsize清空数据库(不会清空已经持久化的数据)
1
2flushdb #清除当前数据库
flushall #清除全部数据库keys * #查看所有的key set <key> <value> #设置键值对 get <key> #获取key对应的value值 exists <key> #查看指定key是否存在 move <key> <db_id> #将指定k-v键值对移动至指定数据库 expire <key> <seconds> #指定过期时间 ttl <key> #查看指定key剩余时间 type <key> #查看指定key对应value类型1
2
3
4
5
6
7
8
9
10## Redis配置文件
+ 配置文件对大小写不敏感
可以`include xxx.config`导入多个配置文件
+ 可以通过客户端对配置文件进行修改(如果有密码要求已经认证),如
```bash
config set requirepass "" #修改密码网络
1
2
3bind 127.0.0.1 #绑定ip
protected-mode yes #保护模式
port 6379 #端口通用
1
2
3
4
5
6daemonize yes #守护者进程运行(后台运行)
pidfile /var/run/redis_6379.pid #守护者模式需要指定pid文件
loglevel notice #日志级别: debug verbose notice warning
logfile "" #日志文件名
database 16 #数据库数量
always-show-log yes #是否显示logo快照
持久化:在规定时间内执行多少次操作会持久化到.rdb.aof
1
2
3
4
5
6
7
8save 900 1 #900s内至少1个key修改了一次就进行持久化操作,下面两个同理
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes #异常之后是否继续工作
rdbcompression yes #是否压缩rdb文件,需要消耗cpu资源
rdbchecksum yes #保存rdb文件时是否错误校验
dir ./ # rdb文件保存的位置主从复制
1
2replicaof <masterip> <masterport> #从机配置文件添加主机的ip和端口
masterauth <master-password> #如果主机有认证密码则在这里配置安全
1
requirepass xxx #设置认证密码,默认为空
1
auth xxx #在客户端访问时进行密码认证
客户端限制
1
maxclients 10000 #最大客户端数量
内存
1
2maxmemory <bytes> #最大内存容量
maxmemory-policy noeviction #内存达到上限的策略1
2
3
4
5
6
7#内存策略
volatile-lru #只对设置了过期时间的的key进行lru(默认)
allkeys-lru #删除lru算法的key
volatile-random #随机删除即将过期key
allkeys-random #随机删除
volatile-ttl #删除季建国七的
noeviction #永不过期,返回错误append only模式
1
2
3appendonly no #默认不开启aof模式,而是使用rdb模式
appendfilename "appendonly.aof" #持久化文件的名字
appendfsync everysec #每秒执行一次sync,可能丢失数据,其它选项 always no
Redis数据
五大数据类型
String
String类型操作
1 | append <key> "someString" #向指定key的value字符串后面追加自定义字符串 / 如果当前key不存在就相当于set key value |
int类型操作
1 | incr <key> #i++ 如果指定key不存在则会自动自动设置kv,且v=1 |
对象操作
1 | set user:1 {name:zhangsan,age:3} #以对象形式保存 |
List
可以将其看做一个双向链表,在两头进行操作效率最高
1 | lpush <list> <value> #左入栈(新建list) |
Set
1 | sadd <set> <value> #向set中添加value值对(新建set) |
Hash
key-map,可以存一些变更数据,且更适合对象的存储
1 | hset <map> <key> <value> #给map中填入kv值(新建map) |
Zset
有序集合
可以用来是先重要消息,以及带权重任务
1 | zadd <zset> <score> <value> #给zset插入值score和value |
特殊数据类型
geospatial
地理位置信息geospatial简称GEO
1 | #lot:经度,lat纬度,member详细信息 |
获取附近的人示例:
1 | #获取以北京为中心,500km为半径距离最近的前三个城市的全部信息 |
可用的距离单位:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
底层其实是zset,我们可以使用zset相关命令来操作geo,如:
1 | zrange <ket> left right #查看元素 |
Hyperloglog
基数:不重复的元素

1 | pfadd <key> <value1> <value3> ... #添加数据 |
如果允许容错就可以使用Hyperloglog,不允许容错则使用set()集合或自定义数据类型去重
Bitmaps
位存储

1 | setbit <key> <offset> <value> #给位移量为offset的位置放入元素value,当然value只能为0,1 |
Redis高级特性
Redis的事务
- 为了保持简单,redis事务保证了其中的一致性和隔离性,不满足原子性和持久性;
- 一次性,顺序性,排他性的执行一系列的命令
事务指令
1 | multi #开启事务 |
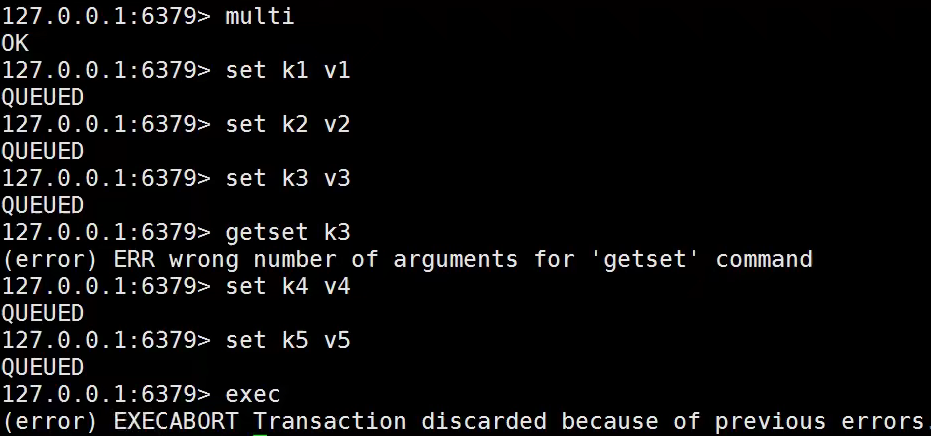
不保证原子性的原因
编译型异常:代码有问题,事务中所有指令都不会执行
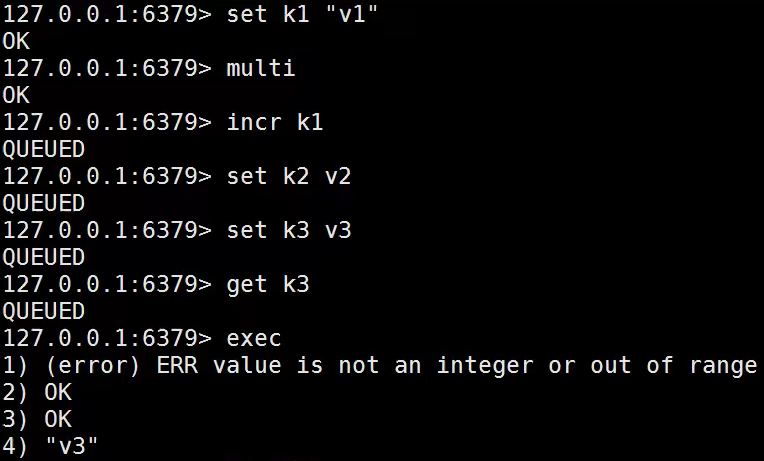
运行时异常:逻辑错误,只有事务中出错的指令不会执行,其他正确指令正常运行
锁
- 悲观锁:认为什么时候都会出问题,任何操作都会加锁
- 乐观锁:认为什么时候都不会出问题,所以不会上锁,更新数据的时候判断数据是否已被修改
Redis监视变量,可以视为乐观锁操作
1 | # 先watch某个key再开启事务,如果exec时key对应的value改变,则事务中的所有指令提交失败,事务回滚 |
如果watch发现value已经改变,事务执行失败:
unwatch先解锁监视watch获取最新值,重新监视- 重新提交事务
订阅发布
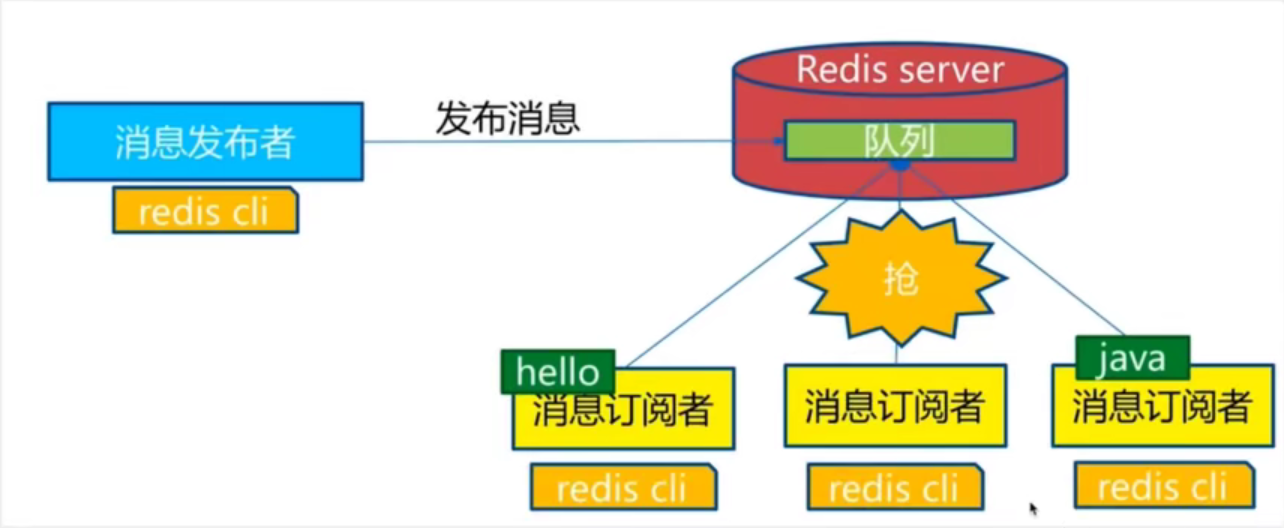
一些常用命令
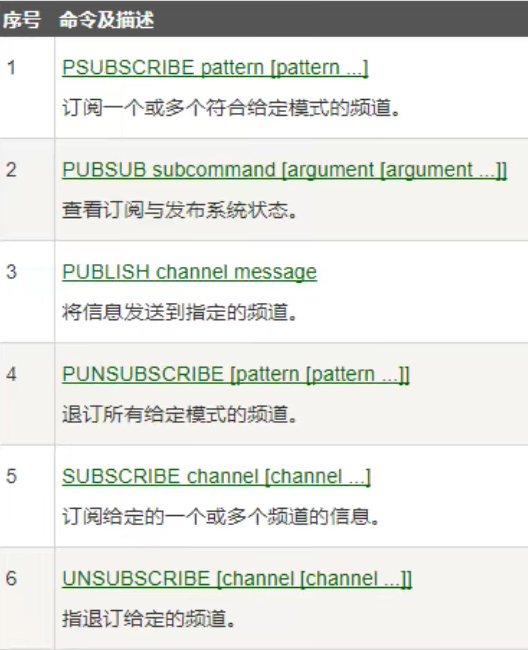

主从复制
基本概念


复制原理

1 | info replication #查看从属关系 |
环境测试
将原配置文件拷贝三份redis-m1.config redis-s1.config redis-s2.config
修改其中的属性:端口,pid,log,dump.rdb
然后分别运行,检查情况

一主二从,在从机的客户端使用命令salveof <ip> <port>使其成为某个主机的从机(暂时),使用salveof no one使其重新变为主机
然后在主机查看结果
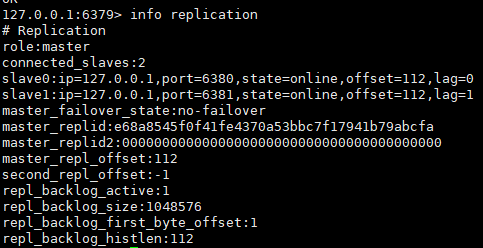
- 只有主机可以进行写操作,从机进行写操作会进行报错,且从机可以读到主机新写入的数据(增量复制)
- 主机断开连接,从机依旧保持从机状态,不能进行写操作,主机如果重新上线,从机依旧可以读取主机写的数据
- 如果是命令行进行的配置,从机重启后会重新变为主机,只要变回从机,会立即从主机中获取值,进行完全复制
主机宕机的解决方案
如果主机m1突然断开连接,如何选取一个新的主机?
手动选取某个从机为主机
salveof no one哨兵模式(自动选取主机的模式)


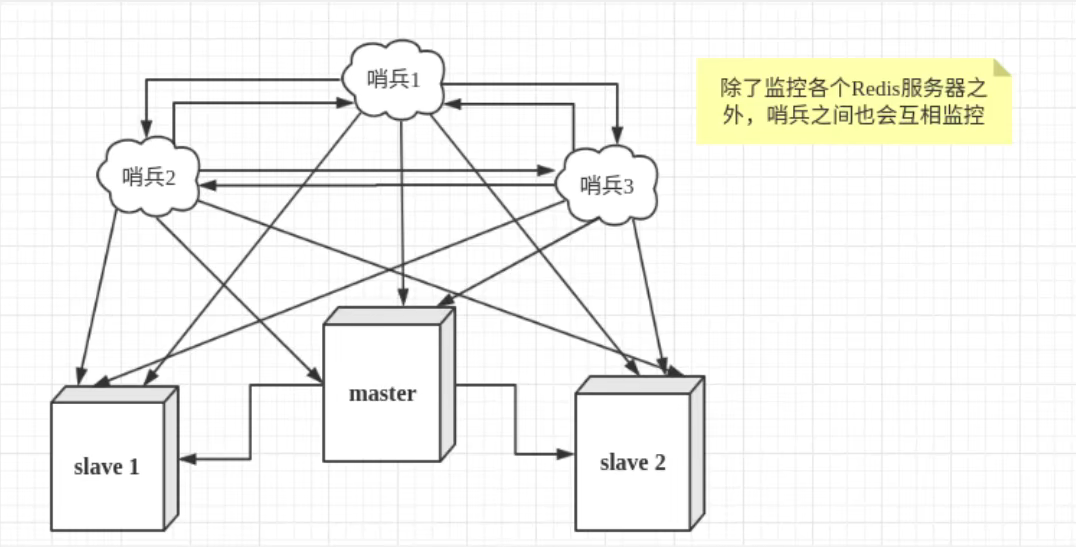

当主机客观下线之后,所有哨兵会根据算法投票选取一个从机成为新的主机
哨兵模式配置文件
sentinel.conf最基础的配置文件可以只配置
sentinel monitor mymaster 127.0.0.1 6379 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
# 最后的1表示总共有1个哨兵观测到宕机就判断主机宕机
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
# 这个数字越小,完成failover所需的时间就越长,
# 但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
# 可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
# 1. 同一个sentinel对同一个master两次failover之间的间隔时间。
# 2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
# 3.当想要取消一个正在进行的failover所需要的时间。
# 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
# 配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
# 对于脚本的运行结果有以下规则:
# 若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
# 若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
# 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
# 一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
# 通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
# 通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh如果主机宕机之后重新启动,他不会重新成为主机,而是成为新主机的一个从机
- 优点:
- 哨兵集群基于主从复制,主从复制的优点都有
- 主从可以切换,故障可以转移,系统可用性更高
- 哨兵模式是主从模式的升级,健壮性更高
- 优点:
缓存穿透与雪崩
服务的高可用问题
缓存穿透
查不到

解决方案
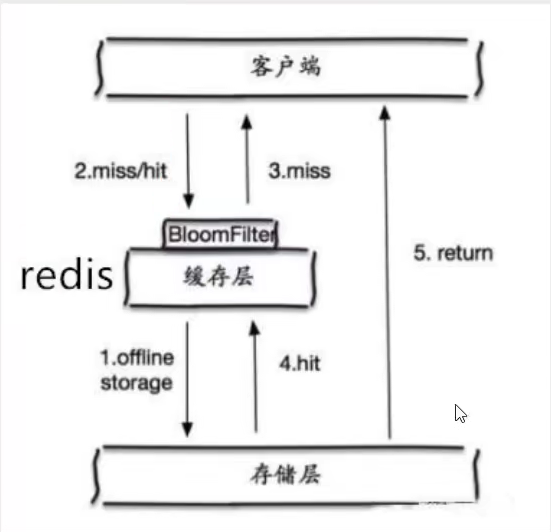
布隆过滤器
是一种数据结构,对所有可能查询的数据以hash形式存储,在控制层先进行校验,不符合则丢弃,避免对底层存储系统的压力
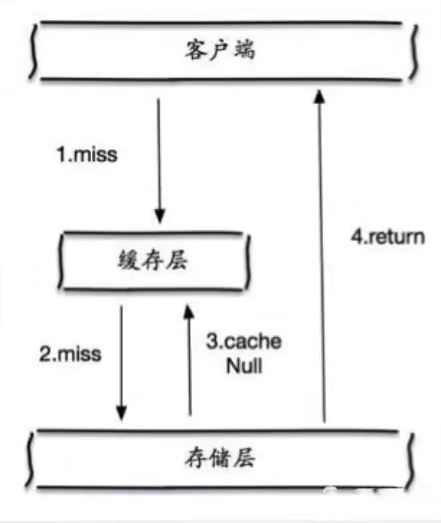
缓存空对象
当存储层不命中后,即使返回空对象也将其缓存起来,并设置过期时间,之后相同的查询请求会从缓存中获取,保护后端数据源
缺点:
- 缓存需要更多地存储空间来保存许多值为空的key
- 即使设置了过期时间,缓存层和存储层的数据还是会存在一段时间的不一致性(缓存中为空但已经向存储层存放了新值),对于需要保持一致性的业务会有影响
缓存击穿
量大,缓存过期

解决方案
设置热点数据不过期
加互斥锁
保证缓存过期后同时仅有一个线程能够查询数据
缓存雪崩
缓存集体失效或Redis宕机
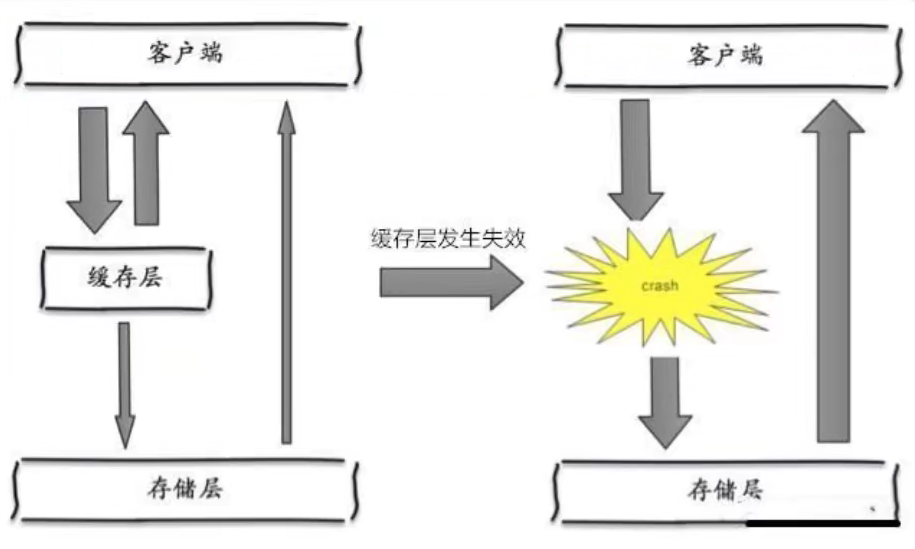
比如双十一:停掉一些服务,保证主要业务可用
解决方案
redis高可用
多设Redis服务器,搭建大型redis集群
限流降级
缓存失效后通过加锁或队列来控制数据库写缓存的线程数量,比如某个key仅允许一个线程查询和写缓存
数据预热
正式部署之前把可能的数据先预先访问一遍,大量访问的数据就会加载到缓存中,在即将发生大的并发访问时手动触发加载不同的key设置不同的过期时间,让缓存失效的时间点尽量均匀
数据淘汰策略
配置文件对应项:maxmemory-policy
Redis提供了5种数据淘汰策略:
- volatile-lru:使用LRU算法进行数据淘汰(淘汰上次使用时间最早的,且使用次数最少的key),只淘汰设定了有效期的key
- allkeys-lru:使用LRU算法进行数据淘汰,所有的key都可以被淘汰
- volatile-random:随机淘汰数据,只淘汰设定了有效期的key
- allkeys-random:随机淘汰数据,所有的key都可以被淘汰
- volatile-ttl:淘汰剩余有效期最短的key
- no-eviction:不进行去主数据,直接报错(默认,但不推荐使用)
Redis4.0新增策略
- volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
- allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
最好为Redis指定一种有效的数据淘汰策略以配合maxmemory设置,避免在内存使用满后发生写入失败的情况。
一般来说,推荐使用的策略是volatile-lru,并辨识Redis中保存的数据的重要性。对于那些重要的,绝对不能丢弃的数据(如配置类数据等),应不设置有效期,这样Redis就永远不会淘汰这些数据。对于那些相对不是那么重要的,并且能够热加载的数据(比如缓存最近登录的用户信息,当在Redis中找不到时,程序会去DB中读取),可以设置上有效期,这样在内存不够时Redis就会淘汰这部分数据。
整合Java
阿里云redis连接失败的原因
- 阿里云安全组策略是否开启对应端口?
- redis-server配置文件中是否绑定0.0.0.0?
- server密码问题
- 服务器防火墙是否开放对应端口,如CentOS7系统:
- 开放防火墙对应端口
firewall-cmd --zone=public --add-port=6379/tcp --permanent - 查看端口开放情况
netstat -ntlp
- 开放防火墙对应端口
Jedis
java实例
导包
1 | <dependency> |
1 | public static void main(String[] args) { |
Jedis事务
1 | public void multi(){ |
整合SpringBoot
1 | <dependency> |
springboot2.x后原来的jedis被替换为了lettuce
- jedis:采用直连方法,多个线程操作是不安全的,避免这种情况需要使用jedis pool,类似BIO模式
- lettuce:采用netty,实例可以在多个线程中共享,不存在线程安全问题,减少线程数据,类似NIO模式
使用默认的RedisTemplate
1 |
|
自定义RedisTemplate
自定义配置类给容器中注入自定义Bean,默认的Bean就会失效
1 |
|
自定义工具类
1 | import org.springframework.beans.factory.annotation.Autowired; |
持久化
RDB(Redis DataBase)
主从复制中rdb可以在从机备用
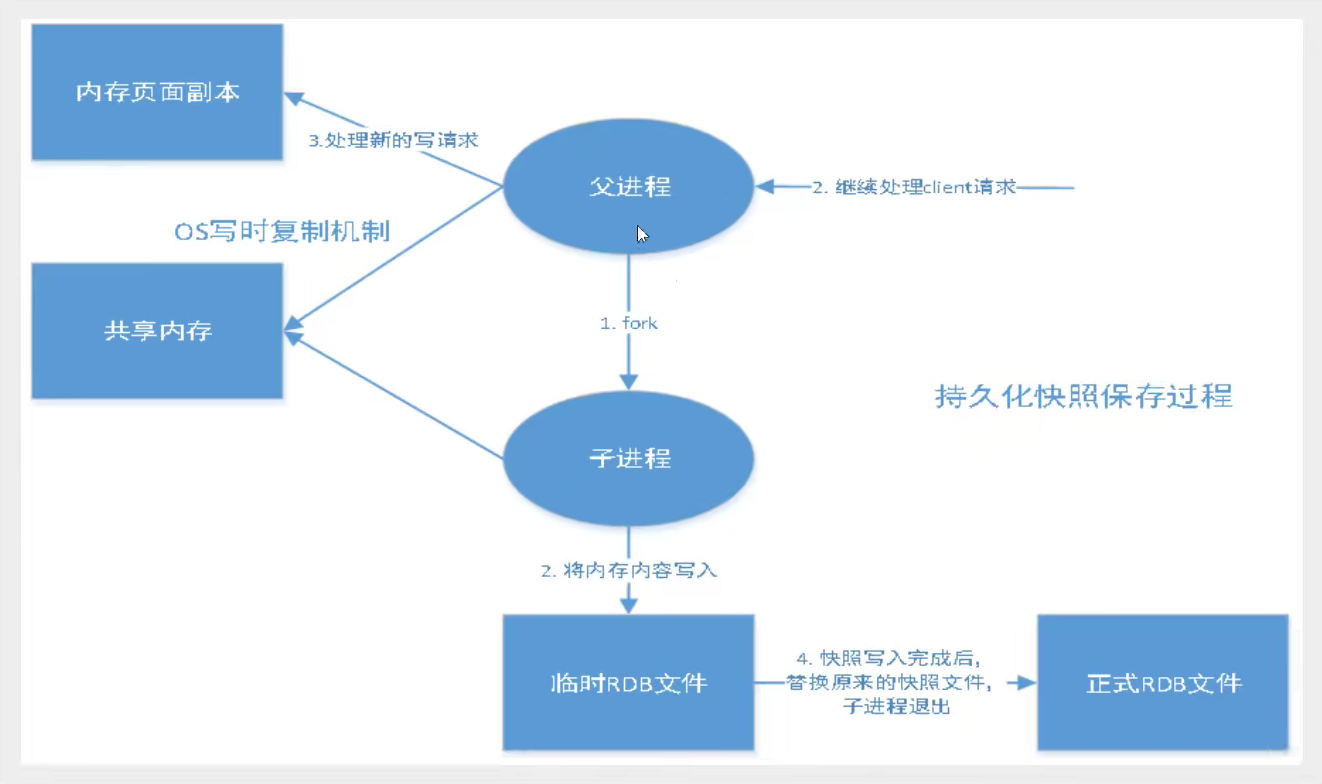

rdb文件命默认为 dump.rdb,可以在配置文件中修改dbfilename进行修改
生成rdb文件的触发规则:
- 满足save规则,自动生成rdb
- 执行
flushall命令,自动生成rdb(flushdb不会) - 退出redis,生成rdb文件
如何恢复rdb文件:
将rdb文件放在redis启动目录,redis启动时会自动检查dump.rdb并恢复其中的数据
查看需要存放的位置
config get dir优点
- 适合大规模数据恢复
- 对数据完整性要求不高
缺点
- 需要一定的时间进行进程操作,如果redis意外宕机,最后一次修改的数据就会消失
- fork进程的时候也会占用一定的内存空间
一般来说,rdb的默认机制就足够我们日常使用了
AOF(Append Only File)
将我们所有的命令都几乎下来,相当于history,恢复时即将所有命令全部记录下来
aof文件命默认为 appendonly.aof,可以在配置文件中修改dbfilename进行修改
默认不开启,需要手动更改配置文件中
appendonly修改为yes进行开启优点(三种不同的同步策略)
- 每一次修改都同步,文件完整性好
- 每秒同步一次,可能丢失一秒的数据
- 从不同步,效率最高
缺点
- 相对于数据文件来说,aof远远大于rdb,修复速度也比rdb慢
- aof运行效率也比rdb慢,因此redis默认配置就是rdb持久化
扩展

